
在当今这个时代,我们面对的是蓬勃发展的数字经济,这直接带来的就是海量数据的涌现。据IDC预测,全球已经进入了数字经济时代,到2021年,至少50%的全球GDP将会由数字化驱动。通过数据驱动业务创新成为企业在数字经济中赢得市场竞争的关键,而从数据中获取价值就需要以人工智能为代表的新技术作为抓手,这也是现在人工智能技术快速发展的原动力。
以数据为中心,构建融合IT基础设施
基于这样的数据现状,英特尔从CPU延展到以数据为中心,致力于实现更快的数据传输,更强的数据存储,更全数据计算。英特尔指数思维推动全面计算创新,保持原有趋势,将摩尔定律的精髓发扬光大。
在业务转型的驱动下,企业面对日益增加的计算需求,持续多样化的工作负载需求比如人工智能、数据分析、网络、虚拟化、高性能计算、安全、数据库、核心IT应用等。英特尔打造以数据为中心的基础设施基石,数据传输更快,数据存储更强,数据计算更全,通过软件和系统级的优化,为用户提供无以伦比的选择和灵活性。

英特尔以数据为中心的策略以一种平衡的方式把计算、存储、网络,以打造架构的方式,针对不同的工作负载,推出系统级的解决方案。以数据为中心让英特尔不再局限于计算层面,而是将计算与存储、网络等进行有机融合,更好地帮助企业构建强有力的IT基础设施,迎接数据大爆炸的挑战。
超异构计算,加速数据价值实现
算力在数据价值实现方面的作用是不言而喻的,而人工智能时代的海量计算需求、算法迭代让传统的通用CPU“应接不暇”,于是异构计算芯片受到关注,并快速发展。但是随着AI的深入,传统的异构计算也慢慢出现“瓶颈”。
“当我们展望下一个十年,或者更长远的未来,随着人工智能应用的愈加广泛和深入,传统的异构计算已经不能满足日益发展的人工智能计算需求,我们正在迈入超异构计算时代。”这是英特尔对于未来计算的思考判断。
在AI时代,我们面临的应用和工作负载日趋多样化,对应承载的平台也需要异构化。英特尔以制程和封装、架构、内存和存储、互连、安全、软件这六大技术支柱来应对未来数据量的爆炸式增长、数据的多样化以及处理方式的多样性。这六大技术支柱是互相相关、紧密耦合的,驱动英特尔的产品持续创新,支撑着未来以数据为中心的业务的持续演进。
英特尔能够提供多样化的标量、矢量、矩阵和空间架构组合,以先进制程技术进行设计,由颠覆性内存层次结构提供支持,通过先进封装集成到系统中,使用光速互连进行超大规模部署,提供统一的软件开发接口以及安全功能,从而实现超异构计算的技术愿景。
正是对于未来计算趋势的把握,英特尔在产品维度进行了积极布局,不管是丰富已有产品功能,还是拓展更多产品领域,英特尔希望AI on IA,加速数据价值的实现。
AI on IA,AI就绪变得如此轻松
英特尔亚洲人工智能销售技术总监伊红卫告诉记者,AI是英特尔公司级的战略,简单来说是三个方面——硬件、软件、生态。在硬件方面,英特尔AI计算平台覆盖从端到边缘到云,提供最完整和灵活的硬件产品组合,包括VPU、FPGA、CPU、GPU、NNP。在软件方面,将提供OneAPI解决方案,实现异构的统一编程和部署。
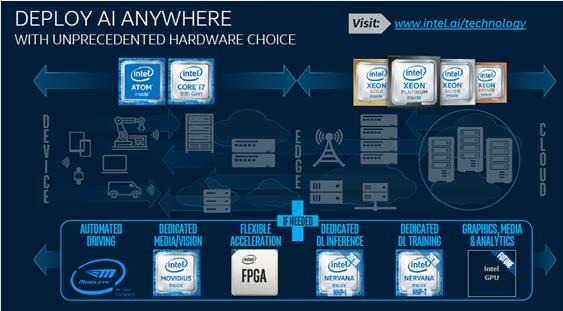
特别是英特尔第二代至强可扩展处理器集成了英特尔深度学习加速(英特尔DL Boost)技术,以加速数据中心、企业和智能边缘计算环境中的人工智能推理工作负载。英特尔DL Boost是一套旨在加快人工智能深度学习速度的处理器技术。DL Boost基于AVX-512扩展新的矢量神经网络指令集(VNNI),性能提升是数量级的,它的导入,使得用户在执行INT8推理时,对系统内存的要求最大可减少75%,而对内存和所需带宽的减少,也加快了低数值精度运算的速度,从而使系统整体性能获得大幅提升, 从而具有更好的TCO,为终端用户提供更一致性的体验。基于DL Boost加速指令集,英特尔至强可扩展处理器在某些AI推理计算中超越GPU加速器方案。
例如,在不影响预测准确度的情况下,百度在其飞桨深度学习平台中基于第二代英特尔至强可扩展处理器平台可使多个深度学习模型在使用INT8时的推理速度,加速到使用FP32时的2-3倍之多,大大提升了用户深度学习应用的工作效能。
伊红卫表示,英特尔会进行大量的测试,从而确保产品性能表现,这种测试包括与合作伙伴的联合创新,也包括与最终用户的合作。伊红卫还列举了一个客户案例,在没有加速卡的情况,英特尔至强处理器在人工智能工作负载中的表现非常出色,完全打消了客户的顾虑。“英特尔在性能测试方面遵循严谨的态度,所有性能测试均基于真实的应用场景,确保客户获得的也是真实的产品性能。”
“当我们面对客户的时候,其实是关注他们所面临的问题。客户是带着问题来找你的,他们其实不会太关注底层技术,但是作为英特尔需要确保产品能够支撑客户的业务应用。英特尔至强处理器正在成为‘多面手’,而且做得很好。这对于客户来说意义重大,特别是在成本方面。”伊红卫说。
FPGA(现场可编程逻辑门阵列)是一种高性能、低功耗可编程芯片。相比于CPU和GPU,其计算效率更高,开发者可实现快速编程验证并进行部署。当前,FPGA在AI芯片中发展迅猛。2015年6月,英特尔宣布以167亿美元的价格,收购全球第二大FPGA厂商Altera。现在,英特尔FPGA提供了一种经济高效的可重复编程平台,从网络边缘到数据中心加速应用。比如Microsoft部署英特尔Stratix10 FPGA,以在Microsoft Azure for Project Brainwave上提供实时人工智能硬件微服务。
在边缘AI方面,英特尔推出了神经计算棒二代(NCS 2)NCS 2计算棒基于Movidius Myriad X视觉处理单元(VPU),利用该计算棒可以在网络边缘构建AI算法和计算机视觉原型设备,并支持英特尔OpenVINO工具包。未来物联网的边缘芯片都会具备一定的处理能力,在前端加强推理AI。业界有很多采用英特尔VPU的应用场景,比如智能楼宇、零售货架等。
伊红卫表示,AI就像水电一样无处不在,而且AI的跨度很大,一个通用的产品肯定不能适配所有场景。所以,英特尔不管是加强自身产品,还是通过收购拓展更多产品领域,都是为了用户提供多样化的产品组合。比如Nervana神经网络处理器(NNP,Neural Network Processor)。
在2019百度AI开发者大会上,英特尔宣布正在与百度合作开发用于AI训练的新Nervana神经网络处理器,也称为NNP-T。NNP-T针对图像识别进行了优化,芯片上的内存由软件直接管理。NNP-T的24个计算集群、32GB的HBM2栈和本地SRAM使其能够提供最多10倍于竞争显卡的人工智能训练性能,以及该公司首款NNP芯片Lake Crest 3-4倍的性能。
NNP-T由于其高速的片内和片外互连,能够将神经网络参数分布到多个芯片上,从而实现很高的并行度。此外,它还使用了一种新的数据格式——BFLOAT16,这种格式可以提高推理任务中至关重要的标量计算,使NNP-T能够适应大型的机器学习模型。据了解,16nm NNP-T预计将在今年晚些时候与10nm Nervana神经网络推理处理器(NNP-I)一起上市。
此外,英特尔公司一直在研发能够模仿人类大脑的Loihi“神经拟态”深度学习芯片。现在,英特尔还推出了一个名为“PohoikiBeach”的新系统,该系统包含多达64颗Loihi芯片,集成了1320亿个晶体管,总面积3840平方毫米,拥有800万个神经元、80亿个突触,能够处理人工智能算法,与普通CPU相比,速度快了1000倍,能效高了10000倍,可用于自动驾驶等。
Loihi芯片采用14nm工艺制造,集成21亿个晶体管,核心面积60平方毫米,内部集成3个Quark x86 CPU核心、128个神经拟态计算核心、13万个神经元、1.3亿个突触,并有包括Python API在内的编程工具链支持。
从直观上看,英特尔的AI产品组合令人“目不暇接”。伊红卫说,不管是已经推出的产品,还是在研发中的产品,英特尔希望为客户提供更多选择。“我们在内部倡导One Intel,所以虽然产品线众多,但是大家都是以客户为中心,聆听客户的心声,帮助客户更好地服务他们的客户。”
结语
以数据为中心,我们在算力方面需要足够的就绪准备。在未来的超异构计算时代,英特尔不断丰富自身的AI产品组合,让用户具备多样化的选择机会。从VPU、FPGA、CPU、GPU、NNP到AI专属芯片,英特尔构建了一个多层面、多维度的产品组合,让客户拿来即用,各取所需。
更为重要的是软硬件协同创新,让AI on IA帮助企业轻松应用人工智能,并且保证高速数据传输,可靠数据存储,高效数据计算从而实现资源的高效利用,让人工智能与企业业务进行融合,促进业务的创新。








